First things first, even if in a Parent/Child situation as the one of the POs most of the examples deal with reports based on Parent & Chidren information together, it’s a good idea to start understanding first the Parent and then the Child element, in this case the PO Header and then the PO Lines. A query on PO Headers would include also the referenced tables – Vendors, Shipment Methods, Employees, etc. In case of big tables a query would typically include the most important attributes, while from referenced tables are included the most used elements.
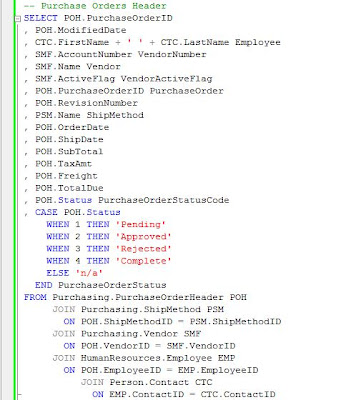 Before further using the query it’s always a good idea to check the variations in cardinality starting from the main table, and increasingly with each join, this test allowing identifying the incorrect joins. When a WHERE clause is involved, it’s easier to use the comment characters (/* … */) and uncomment each join gradually.
Before further using the query it’s always a good idea to check the variations in cardinality starting from the main table, and increasingly with each join, this test allowing identifying the incorrect joins. When a WHERE clause is involved, it’s easier to use the comment characters (/* … */) and uncomment each join gradually.
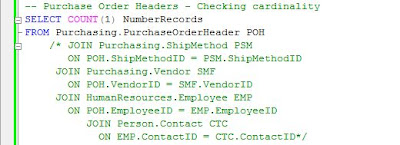 Sometimes it makes sense to encapsulate the query in a view, allowing thus to reuse the logic when needed, minimize maintainability, enforce vertical and horizontal security – to mentioned just a few of views’ benefits. It’s said that views are coming with a slight decrease in performance, though there is always a trade between performance and reusability, including in OOP. It’s recommended to use query writing best practices and target to design your queries for the best performance. Excepting the columns from the initial query, in a view it’s recommended to add also the IDs used in the joins, for faster records filtering or for easier troubleshooting. I prefer to add them in front of the other attributes, though their use could be facilitated when grouped together with the attributes from the table referenced.
Sometimes it makes sense to encapsulate the query in a view, allowing thus to reuse the logic when needed, minimize maintainability, enforce vertical and horizontal security – to mentioned just a few of views’ benefits. It’s said that views are coming with a slight decrease in performance, though there is always a trade between performance and reusability, including in OOP. It’s recommended to use query writing best practices and target to design your queries for the best performance. Excepting the columns from the initial query, in a view it’s recommended to add also the IDs used in the joins, for faster records filtering or for easier troubleshooting. I prefer to add them in front of the other attributes, though their use could be facilitated when grouped together with the attributes from the table referenced.
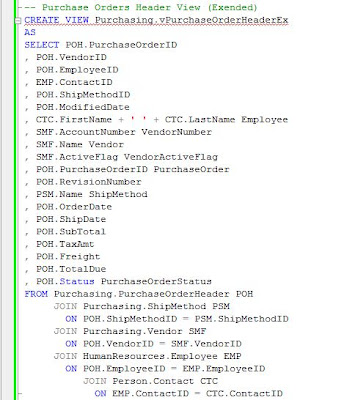 Probably you wonder what’s the meaning of Ex postfix, as you probably deducted from the comment, it stands for Extended. In general I prefer to create a view for each level of detail, in this case one for PO Headers and another one for PO Details, and to use nested views when the decrease in performance is minimal, or especially when the views include complex logic I don’t want to replicate. In addition the views could be reused by Users who don’t have to replicate the logic already included in view, making the analysis of data much easier. On the other side, when using views from various modules (e.g. Account Payables vs Pos, Sales vs. Pos), there are many elements which arrive to be used more than once, in general Master Data (e.g. Products, Vendors, Customers, Locations, etc.), thus in order to avoid these type of not necessary joins, I prefer to partition logically the views – two views won’t contain similar data, though this doesn’t mean that won’t be views that contradict this rule.
Probably you wonder what’s the meaning of Ex postfix, as you probably deducted from the comment, it stands for Extended. In general I prefer to create a view for each level of detail, in this case one for PO Headers and another one for PO Details, and to use nested views when the decrease in performance is minimal, or especially when the views include complex logic I don’t want to replicate. In addition the views could be reused by Users who don’t have to replicate the logic already included in view, making the analysis of data much easier. On the other side, when using views from various modules (e.g. Account Payables vs Pos, Sales vs. Pos), there are many elements which arrive to be used more than once, in general Master Data (e.g. Products, Vendors, Customers, Locations, etc.), thus in order to avoid these type of not necessary joins, I prefer to partition logically the views – two views won’t contain similar data, though this doesn’t mean that won’t be views that contradict this rule.
Using the logical partitioning of views, an alternative view on PO Headers would be created without showing the Vendor end Employee information, following to use if necessary the corresponding views when needed. AdventureWorks includes a view on Vendors called Purchasing.vVendor though the level of detail is at Contact level, and a Vendor could have more than one contacts, therefore the view can’t be used for this purpose, following to create a second view called Purchasing.vVendors (if the name creates confusion you could rename it or rename the Purchasing.vVendor to reflect the fact that the level is Vendor Contacts, for example Purchasing.vVendorContacts).
 The problem with the Purchasing.vPurchaseOrderHeaderEx view is that if a user needs additional information about Vendors not available in the view, I’ll have to add the attributes, arriving in the end to create most of the logic available in Purchasing.vVendors view, or the User will rejoin the Purchasing.vVendors view with Purchasing.vPurchaseOrderHeaderEx, having a redundant link to Vendors. The simplified version of the view is the following:
The problem with the Purchasing.vPurchaseOrderHeaderEx view is that if a user needs additional information about Vendors not available in the view, I’ll have to add the attributes, arriving in the end to create most of the logic available in Purchasing.vVendors view, or the User will rejoin the Purchasing.vVendors view with Purchasing.vPurchaseOrderHeaderEx, having a redundant link to Vendors. The simplified version of the view is the following:
 Now the three views - Purchasing.vVendors, HumanResources.vEmployee and Purchasing.vPurchaseOrderHeader could be joined in a query to obtain the same result as Purchasing.vPurchaseOrderHeaderEx view, this approach offering much more flexibility, even if the decrease in performance is higher, though the performance should be in theory better than joining Purchasing.vPurchaseOrderHeader_Ex with Purchasing.vVendors and HumanResources.vEmployee in order to cover the missing attributes. Unfortunately there is another small hitch – the HumanResources.vEmployee view doesn’t contain the ContactID, therefore the view needing to be modified in case is needed.
Now the three views - Purchasing.vVendors, HumanResources.vEmployee and Purchasing.vPurchaseOrderHeader could be joined in a query to obtain the same result as Purchasing.vPurchaseOrderHeaderEx view, this approach offering much more flexibility, even if the decrease in performance is higher, though the performance should be in theory better than joining Purchasing.vPurchaseOrderHeader_Ex with Purchasing.vVendors and HumanResources.vEmployee in order to cover the missing attributes. Unfortunately there is another small hitch – the HumanResources.vEmployee view doesn’t contain the ContactID, therefore the view needing to be modified in case is needed.
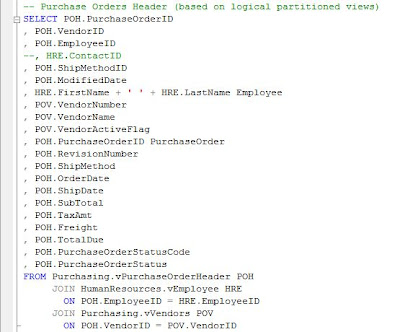 The logical partitioning allows also more flexibility and relatively increased performance when doing data analysis, for example in order to get the volume purchased per Vendor, the Purchasing.vPurchaseOrderHeader could be used to aggregate the data and join the resulting dataset with Purchasing.vVendors view.
The logical partitioning allows also more flexibility and relatively increased performance when doing data analysis, for example in order to get the volume purchased per Vendor, the Purchasing.vPurchaseOrderHeader could be used to aggregate the data and join the resulting dataset with Purchasing.vVendors view.
 A second look at the same sets of data, Vendors and PO Headers, could be based on a left join between the two, thus seeing also the Vendors for which no PO was approved or completed; the query could be used to return the same data as the previous data set (see ‘Vendors with Pos’ constraint). This second query offers greater flexibility, coming with a small decrease in performance and, in addition, must be taken care of NULL values.
A second look at the same sets of data, Vendors and PO Headers, could be based on a left join between the two, thus seeing also the Vendors for which no PO was approved or completed; the query could be used to return the same data as the previous data set (see ‘Vendors with Pos’ constraint). This second query offers greater flexibility, coming with a small decrease in performance and, in addition, must be taken care of NULL values.
 The above examples were showing the cumulated values at Vendor level, what happens when we need to aggregate the data at CountryRegionName level? For this purpose could be used any of the two above queries, and simply aggregate the data at CountryRegionName level. Given the fact that the second query provides greater flexibility, it could be encapsulated in view (e.g. , thus allowing to easily aggregate the data at any level we want – CountryRegionName, StateProvinceName or even City.
The above examples were showing the cumulated values at Vendor level, what happens when we need to aggregate the data at CountryRegionName level? For this purpose could be used any of the two above queries, and simply aggregate the data at CountryRegionName level. Given the fact that the second query provides greater flexibility, it could be encapsulated in view (e.g. , thus allowing to easily aggregate the data at any level we want – CountryRegionName, StateProvinceName or even City.
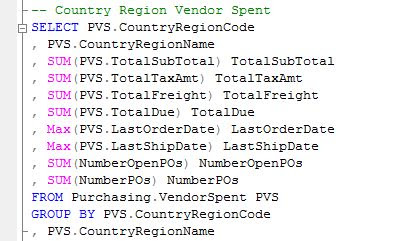 Sometimes simple aggregations are not enough, Users needing more from the data – for example seeing which is the last/first (open) PO placed in the system for each Vendor. Such a report looks simple as request, though not always so easy to provide. Before the introduction of window functions in SQL Server and analytic functions in Oracle, the techniques for such requests were not so elegant… Here it is the SQL server implementation using RANK ranking window function in order to get the Last/First PO, the same aggregated amounts from the previous query being shown with the help of aggregate window functions.
Sometimes simple aggregations are not enough, Users needing more from the data – for example seeing which is the last/first (open) PO placed in the system for each Vendor. Such a report looks simple as request, though not always so easy to provide. Before the introduction of window functions in SQL Server and analytic functions in Oracle, the techniques for such requests were not so elegant… Here it is the SQL server implementation using RANK ranking window function in order to get the Last/First PO, the same aggregated amounts from the previous query being shown with the help of aggregate window functions.
 Note:
Note:
Most of the data analysis focuses only for a certain list of vendors, countries or regions, for a certain time interval, or for any other special requirements, for example pending Pos , in order to approximate the future expenses, or for the rejected Pos, in order to see the volume of waste/rework or to quantify the lost opportunities. The above queries were created for general cases and they could be modified for specific requirements if needed.
 Before further using the query it’s always a good idea to check the variations in cardinality starting from the main table, and increasingly with each join, this test allowing identifying the incorrect joins. When a WHERE clause is involved, it’s easier to use the comment characters (/* … */) and uncomment each join gradually.
Before further using the query it’s always a good idea to check the variations in cardinality starting from the main table, and increasingly with each join, this test allowing identifying the incorrect joins. When a WHERE clause is involved, it’s easier to use the comment characters (/* … */) and uncomment each join gradually.
 Sometimes it makes sense to encapsulate the query in a view, allowing thus to reuse the logic when needed, minimize maintainability, enforce vertical and horizontal security – to mentioned just a few of views’ benefits. It’s said that views are coming with a slight decrease in performance, though there is always a trade between performance and reusability, including in OOP. It’s recommended to use query writing best practices and target to design your queries for the best performance. Excepting the columns from the initial query, in a view it’s recommended to add also the IDs used in the joins, for faster records filtering or for easier troubleshooting. I prefer to add them in front of the other attributes, though their use could be facilitated when grouped together with the attributes from the table referenced.
Sometimes it makes sense to encapsulate the query in a view, allowing thus to reuse the logic when needed, minimize maintainability, enforce vertical and horizontal security – to mentioned just a few of views’ benefits. It’s said that views are coming with a slight decrease in performance, though there is always a trade between performance and reusability, including in OOP. It’s recommended to use query writing best practices and target to design your queries for the best performance. Excepting the columns from the initial query, in a view it’s recommended to add also the IDs used in the joins, for faster records filtering or for easier troubleshooting. I prefer to add them in front of the other attributes, though their use could be facilitated when grouped together with the attributes from the table referenced.
 Probably you wonder what’s the meaning of Ex postfix, as you probably deducted from the comment, it stands for Extended. In general I prefer to create a view for each level of detail, in this case one for PO Headers and another one for PO Details, and to use nested views when the decrease in performance is minimal, or especially when the views include complex logic I don’t want to replicate. In addition the views could be reused by Users who don’t have to replicate the logic already included in view, making the analysis of data much easier. On the other side, when using views from various modules (e.g. Account Payables vs Pos, Sales vs. Pos), there are many elements which arrive to be used more than once, in general Master Data (e.g. Products, Vendors, Customers, Locations, etc.), thus in order to avoid these type of not necessary joins, I prefer to partition logically the views – two views won’t contain similar data, though this doesn’t mean that won’t be views that contradict this rule.
Probably you wonder what’s the meaning of Ex postfix, as you probably deducted from the comment, it stands for Extended. In general I prefer to create a view for each level of detail, in this case one for PO Headers and another one for PO Details, and to use nested views when the decrease in performance is minimal, or especially when the views include complex logic I don’t want to replicate. In addition the views could be reused by Users who don’t have to replicate the logic already included in view, making the analysis of data much easier. On the other side, when using views from various modules (e.g. Account Payables vs Pos, Sales vs. Pos), there are many elements which arrive to be used more than once, in general Master Data (e.g. Products, Vendors, Customers, Locations, etc.), thus in order to avoid these type of not necessary joins, I prefer to partition logically the views – two views won’t contain similar data, though this doesn’t mean that won’t be views that contradict this rule.
Using the logical partitioning of views, an alternative view on PO Headers would be created without showing the Vendor end Employee information, following to use if necessary the corresponding views when needed. AdventureWorks includes a view on Vendors called Purchasing.vVendor though the level of detail is at Contact level, and a Vendor could have more than one contacts, therefore the view can’t be used for this purpose, following to create a second view called Purchasing.vVendors (if the name creates confusion you could rename it or rename the Purchasing.vVendor to reflect the fact that the level is Vendor Contacts, for example Purchasing.vVendorContacts).
 The problem with the Purchasing.vPurchaseOrderHeaderEx view is that if a user needs additional information about Vendors not available in the view, I’ll have to add the attributes, arriving in the end to create most of the logic available in Purchasing.vVendors view, or the User will rejoin the Purchasing.vVendors view with Purchasing.vPurchaseOrderHeaderEx, having a redundant link to Vendors. The simplified version of the view is the following:
The problem with the Purchasing.vPurchaseOrderHeaderEx view is that if a user needs additional information about Vendors not available in the view, I’ll have to add the attributes, arriving in the end to create most of the logic available in Purchasing.vVendors view, or the User will rejoin the Purchasing.vVendors view with Purchasing.vPurchaseOrderHeaderEx, having a redundant link to Vendors. The simplified version of the view is the following:
 Now the three views - Purchasing.vVendors, HumanResources.vEmployee and Purchasing.vPurchaseOrderHeader could be joined in a query to obtain the same result as Purchasing.vPurchaseOrderHeaderEx view, this approach offering much more flexibility, even if the decrease in performance is higher, though the performance should be in theory better than joining Purchasing.vPurchaseOrderHeader_Ex with Purchasing.vVendors and HumanResources.vEmployee in order to cover the missing attributes. Unfortunately there is another small hitch – the HumanResources.vEmployee view doesn’t contain the ContactID, therefore the view needing to be modified in case is needed.
Now the three views - Purchasing.vVendors, HumanResources.vEmployee and Purchasing.vPurchaseOrderHeader could be joined in a query to obtain the same result as Purchasing.vPurchaseOrderHeaderEx view, this approach offering much more flexibility, even if the decrease in performance is higher, though the performance should be in theory better than joining Purchasing.vPurchaseOrderHeader_Ex with Purchasing.vVendors and HumanResources.vEmployee in order to cover the missing attributes. Unfortunately there is another small hitch – the HumanResources.vEmployee view doesn’t contain the ContactID, therefore the view needing to be modified in case is needed.
 The logical partitioning allows also more flexibility and relatively increased performance when doing data analysis, for example in order to get the volume purchased per Vendor, the Purchasing.vPurchaseOrderHeader could be used to aggregate the data and join the resulting dataset with Purchasing.vVendors view.
The logical partitioning allows also more flexibility and relatively increased performance when doing data analysis, for example in order to get the volume purchased per Vendor, the Purchasing.vPurchaseOrderHeader could be used to aggregate the data and join the resulting dataset with Purchasing.vVendors view.
 A second look at the same sets of data, Vendors and PO Headers, could be based on a left join between the two, thus seeing also the Vendors for which no PO was approved or completed; the query could be used to return the same data as the previous data set (see ‘Vendors with Pos’ constraint). This second query offers greater flexibility, coming with a small decrease in performance and, in addition, must be taken care of NULL values.
A second look at the same sets of data, Vendors and PO Headers, could be based on a left join between the two, thus seeing also the Vendors for which no PO was approved or completed; the query could be used to return the same data as the previous data set (see ‘Vendors with Pos’ constraint). This second query offers greater flexibility, coming with a small decrease in performance and, in addition, must be taken care of NULL values.
 The above examples were showing the cumulated values at Vendor level, what happens when we need to aggregate the data at CountryRegionName level? For this purpose could be used any of the two above queries, and simply aggregate the data at CountryRegionName level. Given the fact that the second query provides greater flexibility, it could be encapsulated in view (e.g. , thus allowing to easily aggregate the data at any level we want – CountryRegionName, StateProvinceName or even City.
The above examples were showing the cumulated values at Vendor level, what happens when we need to aggregate the data at CountryRegionName level? For this purpose could be used any of the two above queries, and simply aggregate the data at CountryRegionName level. Given the fact that the second query provides greater flexibility, it could be encapsulated in view (e.g. , thus allowing to easily aggregate the data at any level we want – CountryRegionName, StateProvinceName or even City. Sometimes simple aggregations are not enough, Users needing more from the data – for example seeing which is the last/first (open) PO placed in the system for each Vendor. Such a report looks simple as request, though not always so easy to provide. Before the introduction of window functions in SQL Server and analytic functions in Oracle, the techniques for such requests were not so elegant… Here it is the SQL server implementation using RANK ranking window function in order to get the Last/First PO, the same aggregated amounts from the previous query being shown with the help of aggregate window functions.
Sometimes simple aggregations are not enough, Users needing more from the data – for example seeing which is the last/first (open) PO placed in the system for each Vendor. Such a report looks simple as request, though not always so easy to provide. Before the introduction of window functions in SQL Server and analytic functions in Oracle, the techniques for such requests were not so elegant… Here it is the SQL server implementation using RANK ranking window function in order to get the Last/First PO, the same aggregated amounts from the previous query being shown with the help of aggregate window functions.
 Note:
Note:Most of the data analysis focuses only for a certain list of vendors, countries or regions, for a certain time interval, or for any other special requirements, for example pending Pos , in order to approximate the future expenses, or for the rejected Pos, in order to see the volume of waste/rework or to quantify the lost opportunities. The above queries were created for general cases and they could be modified for specific requirements if needed.
Previous Post <<||>> Next Post


No comments:
Post a Comment