Introduction
Using a single chart to display multiple series in SQL Server Reporting Services (SSRS) or any other reporting tool works well when the number of series is somehow manageable - usually being enough to display 2-10 series within the same chart. The more series one adds, the more complicated will be for users to read the chart. One has the choice to find either
- a level of detail (e.g. Category) which, when grouping the data, leads to a number of manageable series,
- compare the data within a certain grouping (e.g. Category),
- displaying the individual trends (e.g. for each Product).
Let's consider the last choice. The report from this post will display the Sales Volume per Product and Year/Month of the Sales Orders available in the AdventureWorks2014 database. The logic uses the Sales.SalesOrderDetail and Sales.SalesOrderHeader tables, respectively the Production.vProducts view created in a
previous post.
Note:
A Sales Volume report is more appropriate to be built using a data warehouse's data, which are already aggregated and prepared for such reports. There's actually an AdventureWorksDW2014 data warehouse model made available which can be used to display the same information, however the intent is to demonstrate the techniques of working with data in an OLTP environment.
Preparing the Data
Creating a view to build the Sales Orders details is usually recommended, though for the current report we just need the Product Category, Subcategory, Number and Name, respectively Sales Date, Quantity and Value, which is only a small part from the attributes available. Another choice to consider is whether to use the raw data, though then the number of records sent to the client can be considerably high, or aggregate the data and the lowermost level of detail needed for the report, in this case the Category, Subcategory, Product, Month and Year:
-- Sales volume per Product
SELECT ITM.Category
, ITM.Subcategory
, ITM.ProductNumber
, ITM.Name
, Month(SOH.OrderDate) [Month]
, Year(SOH.OrderDate) [Year]
, Sum(SOD.OrderQty) OrderQty
, Sum(SOD.LineTotal) OrderValue
FROM Sales.SalesOrderDetail SOD
JOIN Sales.SalesOrderHeader SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
JOIN Production.vProducts ITM
ON SOD.ProductId = ITM.Productid
WHERE ITM.ProductNumber IN ('BB-7421', 'BB-9108')
GROUP BY ITM.Category
, ITM.Subcategory
, ITM.ProductNumber
, ITM.Name
, Month(SOH.OrderDate)
, Year(SOH.OrderDate)
ORDER BY ITM.Category
, ITM.Subcategory
, ITM.ProductNumber
, [Year]
, [Month]
The query contains all the needed data, however one could have more flexibility if the data would contain cumulative or total values as well:
-- Sales volume per Product (extended)
SELECT SOD.Category
, SOD.Subcategory
, SOD.ProductNumber
, SOD.Name
, SOD.[Month]
, SOD.[Year]
, SOD.OrderQty
, SOD.OrderValue
, SUM(SOD.OrderQty) OVER (PARTITION BY SOD.ProductNumber) TotalQty
, SUM(SOD.OrderValue) OVER (PARTITION BY SOD.ProductNumber) TotalValue
, SUM(SOD.OrderQty) OVER (PARTITION BY SOD.ProductNumber ORDER BY [Year], [Month]) CumulatedQty
, SUM(SOD.OrderValue) OVER (PARTITION BY SOD.ProductNumber ORDER BY [Year], [Month]) CumulatedValue
FROM (-- cumulated values
SELECT ITM.Category
, ITM.Subcategory
, ITM.ProductNumber
, ITM.Name
, Month(SOH.OrderDate) [Month]
, Year(SOH.OrderDate) [Year]
, Sum(SOD.OrderQty) OrderQty
, Sum(SOD.LineTotal) OrderValue
FROM Sales.SalesOrderDetail SOD
JOIN Sales.SalesOrderHeader SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
JOIN [Production].[vProducts] ITM
ON SOD.ProductId = ITM.Productid
WHERE ITM.ProductNumber IN ('BB-7421', 'BB-9108')
GROUP BY ITM.Category
, ITM.Subcategory
, ITM.ProductNumber
, ITM.Name
, Month(SOH.OrderDate)
, Year(SOH.OrderDate)
) SOD
ORDER BY SOD.Category
, SOD.Subcategory
, SOD.ProductNumber
, SOD.[Year]
, SOD.[Month]
In the end one can use any of the above queries.
Note:When prototyping a report is usually recommended to consider only a small number of records (e.g. only two Products). In addition, do not forget to validate the number or records considered by the logic:
-- checking the view for internal data consistency
SELECT count(*)
FROM Sales.SalesOrderDetail SOD
JOIN Sales.SalesOrderHeader SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
JOIN Production.vProducts ITM
ON SOD.ProductId = ITM.Productid
Creating the Report
Using the Report Wizard create a new matrix report called "Sales Volume per Product" based on either of the above queries (I considered the second). Within "Design the Matrix" select the attributes as follows:
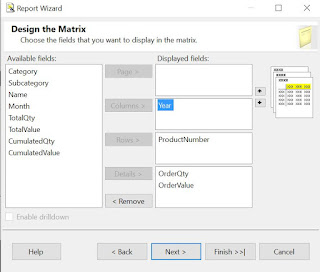 |
| Design the Matrix |
This will create the backbone for our report:
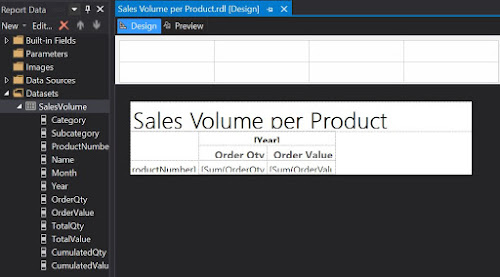 |
| First draft in Design mode |
Which is pretty basic, if we consider the output:
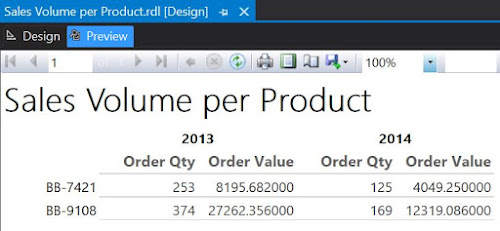 |
| First draft in Preview mode |
Now, returning in Design mode, right click on the "Sum of OrderQty" cell and from the floating menu select Insert/Chart, while from the list of available charts select Line. Do the same for "Sum of OrderValue". And here's the result:
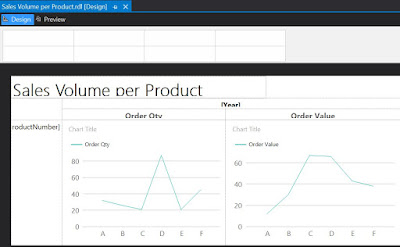 |
| Second draft in Design mode |
As only one series will be displayed, select the Chart Title and delete the respective label. Delete the Series label as well. When running the report you'll observe that the horizontal axis values are not really appealing. To dix this right click on the respective area and from the floating menu select Horizontal Axis Properties. Within Axis Options section change the Axis type as 'Scalar', enter '1' as Minimum, '12' as Maximum, '1' as Interval and 'Number' as Interval type:
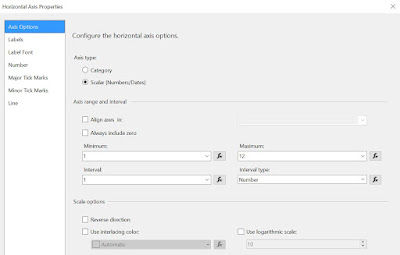 |
| Horizontal Axis Properties |
In the same window, within the Labels section select 'Enable auto-fit' and uncheck the "Labels can be offset", respectively the "Labels can be rotated" checkboxes.
To include the Category, Subcategory and eventually the Product Name, select the Product Number cell, right click on it, and from the floating menu select Insert Column/Inside Group - Left, then select from the Category as attribute:
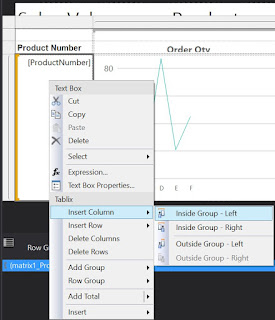 |
| Inserting a column within the group |
Repeat the process to add the Subcategory. Eventually you can add also the Product Name, though for it you'll have to select "Inside Group - Right".
To improve the design, you can add a Page Header and move the report's title into it add a timestamp, respectively a page count textbox, resize the boxes to fit the columns. You can also align the column header values to the center, change the font to 10pt, etc.
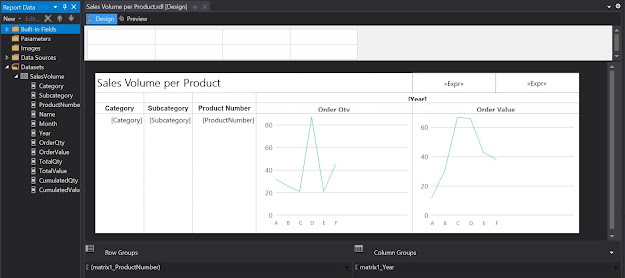 |
| Third draft in Design mode |
Here's the report in preview mode:
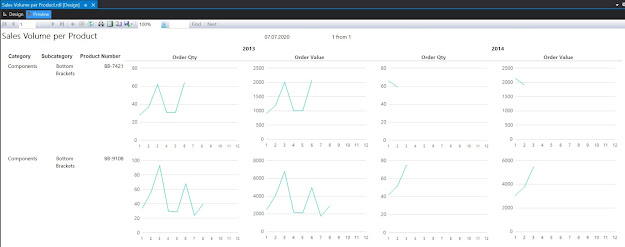 |
| Third draft in Preview mode |
One can use the report the way it is, or add the Category and Subcategory as parameters. Similarly, one can use the cumulative values as input for the charts.
Revamping the Report with Sparklines
Even if the charts allow displaying the scales, the problem with them is that they are too big, which makes it difficult to compare the data across records. One can correct this by using the other types of graphics available in reports, e.g. sparklines. For this make a copy of the report already built, and within the Detail cells select a Sparkine Column instead of a chart:
 |
| Sparkline types |
In comparison with Lines, Column-based representations allow to see how many data points are represented. Because spartklines are more compact as graphic forms, you can resize the cells as follows:
 |
| Fourth draft in Design mode |
And here's the report in preview mode (the constraints from the source query were removed):
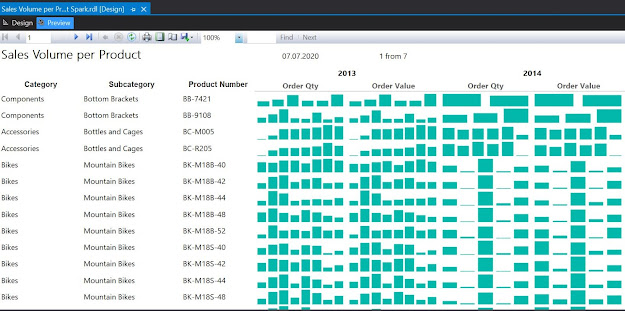 |
| Fourth draft in Preview mode |
As can be seen one can easily identify the trends however the volume scale was lost, being impossible to compare which of the Products sold better. One can bring the Total Quantity and Value as display information and sort the dataset from the highest to lowest value. One can even select a top x, to reduce the focus only to the most sold Products.
If the prices remained relatively constant over time, there's actually almost no difference between the graphic displays for Order Quantity, respectively for Order Value. Therefore one can remove one of them (e.g. Order Quantity). Being more compact, sparkline-based representations allow to better use the space, therefore you can add more fields into the report.
Happy coding!
Previous Post
<<||>>
Next Post


























